
Good morning to all , here is my fifth blog for you on the topic which is most popular and emerging technology used in tech world that is Machine Learning nowadays . So here we start
Table of Contents
Machine Learning

It is a branch of artificial intelligence (AI) and computer science which focuses on the use of data and algorithms to imitate the way that humans learn, gradually improving its accuracy.
The scientific discipline of this field enables computers to learn without explicit programming. One of the most intriguing technologies one has ever encountered is machine learning (ML).
It is an important component of the growing field of data science. Algorithms are trained using statistical techniques to produce classifications or predictions and to find important insights in data mining projects. The decisions made as a result of these insights influence key growth indicators in applications and enterprises, ideally.
Machine learning algorithms are typically created using frameworks that accelerate solution development, such as TensorFlow and PyTorch.
The rising demand for machine learning engineers is a result of developing technology and the production of enormous volumes of data, or “Big Data.” The typical income for an ML Engineer is 719,646 (IND), or $111,490. (US).
Evolution of Machine Learning
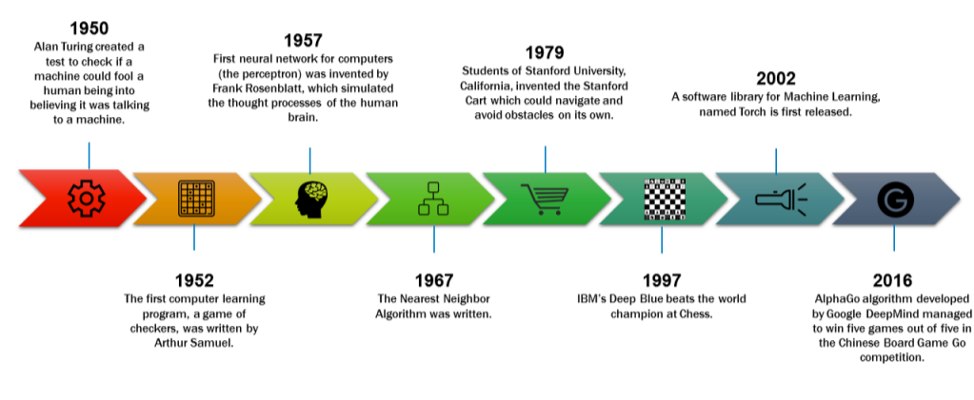
Arthur Samuel created the first educational application for IBM in 1952, and it featured a game of checkers this time. Following Frank Rosenblatt’s 1957 creation of the first neural network and Gerald DeJong’s 1981 introduction of explanation-based learning, several other machine learning pioneers built on their work.
A significant change in machine learning happened in the 1990s when the emphasis shifted from a knowledge-based approach to one driven by data. This decade was crucial in the development of the subject since it marked the beginning of the development of computer programmes that could evaluate massive datasets while also learning.
Unsupervised learning became increasingly popular in the 2000s, eventually paving the way for deep learning to emerge and machine learning to become a common technique.
The defeat of Russian chess grandmaster Garry Kasparov by the IBM supercomputer Deep Blue in 1997 and, more recently, the victory of the Google DeepMind AI programme AlphaGo over Lee Sedol playing Go, a game renowned for its enormously large playable space, are examples of algorithms defeating human performance and serving as milestones in machine learning.
Researchers are currently working hard to build on these discoveries. Applications for machine learning and artificial intelligence are growing in popularity and moving from server-based systems to the cloud, making them more widely available. Google promoted a number of new deep learning and machine learning capabilities at Google Next 2018, including Cloud AutoML, BigQuery ML, and others. Through open source initiatives and business cloud services over the past few years, Amazon, Microsoft, Baidu, and IBM have all released machine learning systems. The capabilities of research and industry are being quickly expanded by machine learning algorithms, which are here to stay.
How it works ?
The fundamental idea behind machine learning in data science is to use statistical learning and optimization techniques to enable computers to study datasets and spot patterns. Data mining is used by machine learning algorithms to uncover historical trends and inform upcoming models.
The typical supervised machine learning algorithm consists of roughly three components:
- A decision process :In general, predictions or classifications are made using machine learning algorithms. Your algorithm will generate an estimate about a pattern in the input data based on some input data, which can be labelled or unlabeled.
- An error function :The model’s prediction is evaluated using an error function. If there are known examples, an error function can compare them to gauge the model’s correctness.
- An updating or optimization process : Weights are changed to lessen the difference between the known example and the model estimate if the model can better fit the data points in the training set. This “evaluate and optimise” procedure will be repeated by the algorithm, with weights being updated automatically, until a predetermined level of accuracy is reached.
Types of Machine Learning Methods
The presence or lack of human intervention in the raw data, such as the provision of rewards, detailed feedback, or labels, determines the many types of models.
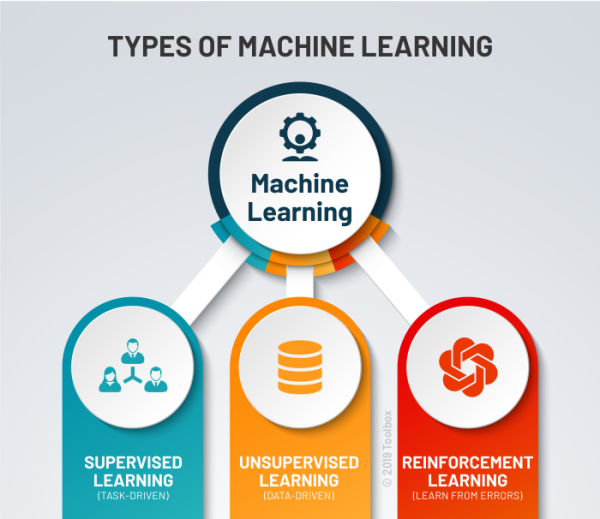
Generally it fall into three primary categories i.e. Supervised Learning , Unsupervised Learning , Reinforcement Learning .
Supervised learning :
The term “supervised learning,” which is also used to refer to supervised machine learning, refers to the process of teaching algorithms to correctly classify data or predict outcomes using labelled datasets. The model modifies its weights as input data is fed into it until it is well fitted. This happens as part of the cross validation procedure to make sure the model does not fit too well or too poorly.
A common example of how supervised learning aids companies is by classifying spam in a distinct folder from your email. Neural networks, naive bayes, linear regression, logistic regression, random forest, and support vector machines are a few techniques used in supervised learning (SVM).
The dataset being used has been pre-labeled and classified by users to allow the algorithm to see how accurate its performance is.
Unsupervised learning :
Unsupervised learning, commonly referred to as unsupervised machine learning, analyses and groups unlabeled datasets using machine learning algorithms. These algorithms identify hidden patterns or data clusters without the assistance of a human.
This strategy is useful for exploratory data analysis, cross-selling tactics, consumer segmentation, and picture and pattern identification since it can find similarities and differences in information. Additionally, dimensionality reduction is used to lower the number of features in a model.
Two popular methods for this are singular value decomposition (SVD) and principal component analysis (PCA). In unsupervised learning, neural networks, k-means clustering, and probabilistic clustering techniques are other algorithms that are used.
The raw dataset being used is unlabeled and an algorithm identifies patterns and relationships within the data without help from users.
Reinforcement learning :
Although the algorithm isn’t trained on sample data, reinforcement machine learning is a machine learning approach that is similar to supervised learning. By making mistakes along the way, this model learns.
The optimal suggestion or strategy will be created for a specific problem by reinforcing a string of successful outcomes.
The dataset uses a “rewards/punishments” system, offering feedback to the algorithm to learn from its own experiences by trial and error.
Semi-supervised learning :
Semi-supervised learning offers a happy medium between supervised and unsupervised learning. During training, it uses a smaller labeled data set to guide classification and feature extraction from a larger, unlabeled data set.
Semi-supervised learning can solve the problem of not having enough labeled data for a supervised learning algorithm. It also helps if it’s too costly to label enough data.
The dataset contains structured and unstructured data, which guides the algorithm on its way to making independent conclusions. The combination of the two data types in one training dataset allows machine learning algorithms to learn to label unlabeled data.
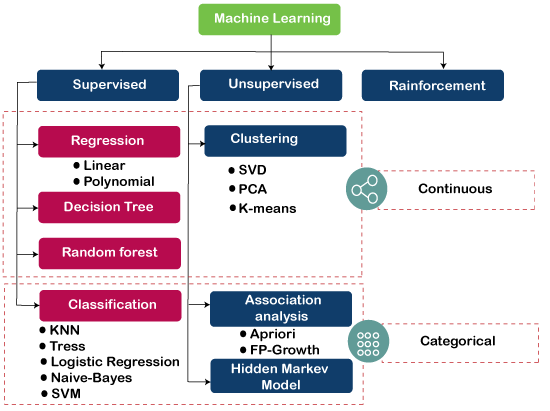
Common Machine Learning Algorithms
The dataset contains structured and unstructured data, which guides the algorithm on its way to making independent conclusions. The combination of the two data types in one training dataset allows machine learning algorithms to learn to label unlabeled data.
A number of machine learning algorithms are commonly used. These include:
- Neural networks : Neural networks, which include a vast number of connected processing nodes, mimic how the human brain functions. Natural language translation, picture identification, speech recognition, and image generation are just a few of the applications that benefit from neural networks’ aptitude for pattern detection.
- Linear regression : Based on a linear relationship between various values, this technique is used to forecast numerical values. The method might be applied, for instance, to forecast housing values based on local historical data.
- Logistic regression : The “yes/no” responses to questions are categorical response variables, and our supervised learning method predicts them. Applications for it include sorting spam and performing quality control on a production line.
- Clustering : Clustering algorithms can find patterns in data to group it via unsupervised learning. Data scientists can benefit from computers’ ability to spot distinctions between data points that humans have missed.
- Decision trees : Decision trees can be used to categorize data into categories as well as forecast numerical values (regression). A tree diagram can be used to show the branching sequence of connected decisions used in decision trees. In contrast to the neural network’s “black box,” decision trees are simple to validate and audit, which is one of their benefits.
- Random forests : The machine learning approach uses a random forest to combine the output from various decision trees to predict a value or category.
Challenges of machine learning
The advancement of machine learning technologies has undoubtedly improved our quality of life. The use of machine learning in business has, however, brought up certain ethical questions regarding AI developments. A few of these are:
Technological singularity
Despite the widespread public interest in this subject, many researchers do not share this fear about the possibility of AI eventually outpacing human intelligence. Strong AI or superintelligence are other terms used to describe the technological singularity. Superintelligence is “any mind that significantly excels the best human brains in nearly every discipline, including scientific innovation, general knowledge, and social abilities,” according to philosopher Nick Bostrum. Superintelligence may not be a reality any time soon, but as we explore the usage of autonomous technologies like self-driving cars, several intriguing concerns about superintelligence are raised.
AI impact on jobs
While the loss of jobs is a major concern for the public when it comes to AI, this fear should probably be reframed. Every disruptive, new technology causes a shift in the market’s demand for particular job roles. For instance, if we take a look at the automobile sector, several manufacturers, like GM, are moving their attention to the development of electric vehicles in order to support green initiatives. Although the energy sector is still around, the energy’s source is changing from a fuel economy to an electric one.
Artificial intelligence will similarly shift the demand for work to other sectors. People will be needed to assist in managing AI systems. In the sectors most likely to be impacted by shifts in employment demand, such as customer service, there will still be a need for employees to handle more complicated issues. aThe biggest difficulty with artificial intelligence and its impact on the labour market will be assisting workers in making the transition to new, in-demand occupations.
Privacy
The topics of data protection, data security, and privacy are frequently brought up when talking about privacy. Policymakers have advanced in recent years thanks to these worries. For instance, GDPR law was developed in 2016 to provide people more control over their data while protecting the personal information of those living in the European Union and European Economic Area. The California Consumer Privacy Act (CCPA), which was launched in 2018 and mandates businesses to tell customers about the acquisition of their data, is one example of a state policy being developed in the United States. As a result, businesses are making security investments a higher priority as they try to close any gaps or openings for monitoring, hacking, and cyberattacks.
Bias and discrimination
Numerous machine learning algorithms have been found to be biassed and discriminatory, which has led to various ethical concerns about the usage of AI. Additionally, bias and discrimination are not only present in the human resources department; they are also present in many other applications, such as social media algorithms and facial recognition software.
Businesses have been more involved in the debate over AI ethics and values as they become more aware of the concerns associated with AI. “IBM firmly opposes and will not tolerate uses of any technology, including facial recognition technology offered by other vendors, for purposes such as mass surveillance, racial profiling, violations of fundamental human rights and freedoms, or any other purpose which is inconsistent with our values and Principles of Trust and Transparency,” wrote IBM CEO Arvind Krishna in a statement.
Accountability
There isn’t much regulation to control how AI is used, hence there isn’t much of an enforcement system to make sure AI is used ethically. The financial consequences of an unethical AI system are the existing incentives for businesses to be moral. As a result of the collaboration between ethicists and researchers, ethical frameworks have developed to control the creation and dissemination of AI models within society. But at the moment, they merely act as guidelines.
Hope you enjoyed reading this blog . For more Read out Real life applications and opportunities in machine learning . For more daily blogs visit our site.



